
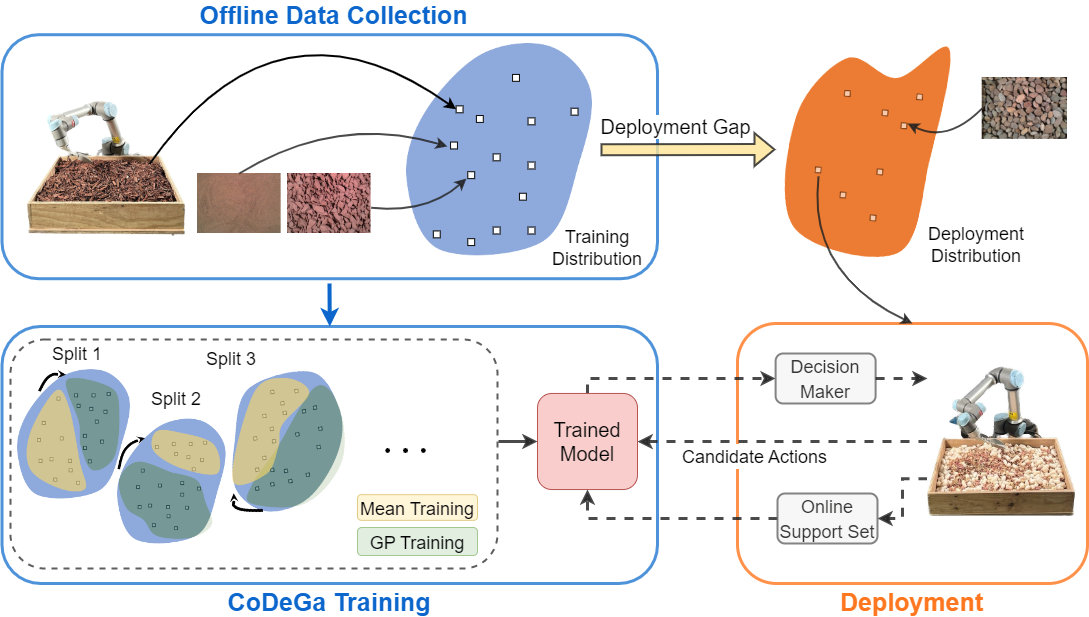
Autonomous lander missions on extraterrestrial bodies will need to sample granular material while coping with domain shift, no matter how well a sampling strategy is tuned on Earth. This paper proposes an adaptive scooping strategy that uses deep Gaussian process method trained with meta-learning to learn on-line from very limited experience on the target terrains. It introduces a novel meta-training approach, Deep Meta-Learning with Controlled Deployment Gaps (CoDeGa), that explicitly trains the deep kernel to predict scooping volume robustly under large domain shifts.
Employed in a Bayesian Optimization sequential decision-making framework, the proposed method allows the robot to use vision and very little on-line experience to achieve high-quality scooping actions on out-of-distribution terrains, significantly outperforming non-adaptive methods proposed in the excavation literature as well as other state-of-the-art meta-learning methods.
Moreover, a dataset of 6,700 executed scoops collected on a diverse set of materials, terrain topography, and compositions is made available for future research in granular material manipulation and meta-learning.
The scooping dataset contains 6700 executed scoops and their corresponding observations collected over a diverse set of materials, terrain topography, and compositions. The dataset can be downloaded at this link.
We organized the dataset in a easy-to-use format and provided some additional files quickly get started with it. The dataset is publicly available for download at this link. The download link contains the following files:
readme.md: A README file that provides details of the dataset organization and different attributes of the dataset.terrains.csv: A CSV file containing the terrain IDs, the materials used in them, and the terrain compositions.train_examples.py: A Python script that shows a simple training pipeline to load the dataset and access the data to train an example model.dataset.zip: The dataset in a compressed format. The dataset is organized as shown in the directory tree below.
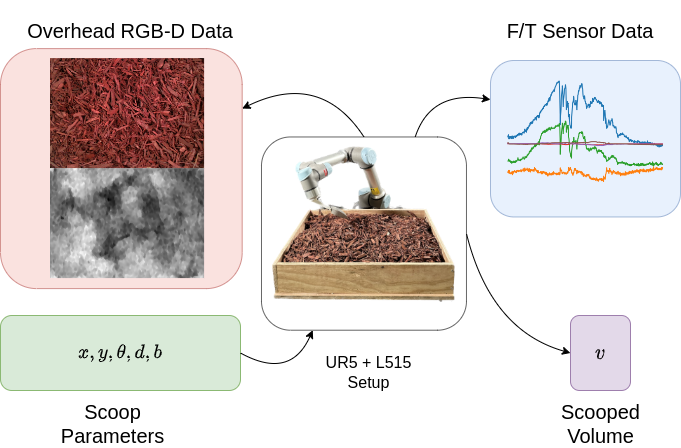
1_rgbd.npy to 100_rgbd.npy: The RGB-D images of the terrain. The first 3 channels correspond to the RGB channels and the 4th channel corresponds to the depth channel.1_ft.npy to 100_ft.npy: The F/T sensor data captured during the scoop action while the end-effector was in contact with the terrain.actions_outcomes.npy: The actions and outcomes all 100 samples in the terrain.Each sample in the dataset contains an action (scoop location, scoop yaw, scoop depth, and scoop stiffness), the state of the terrain (RGBD data) before scooping, the volume scooped with the action, and the end-effector F/T sensor data captured while executing the scooping action. We use UR5e to execute the scoop and an overhead RealSense L515 to capture the RGBD data of the environment.
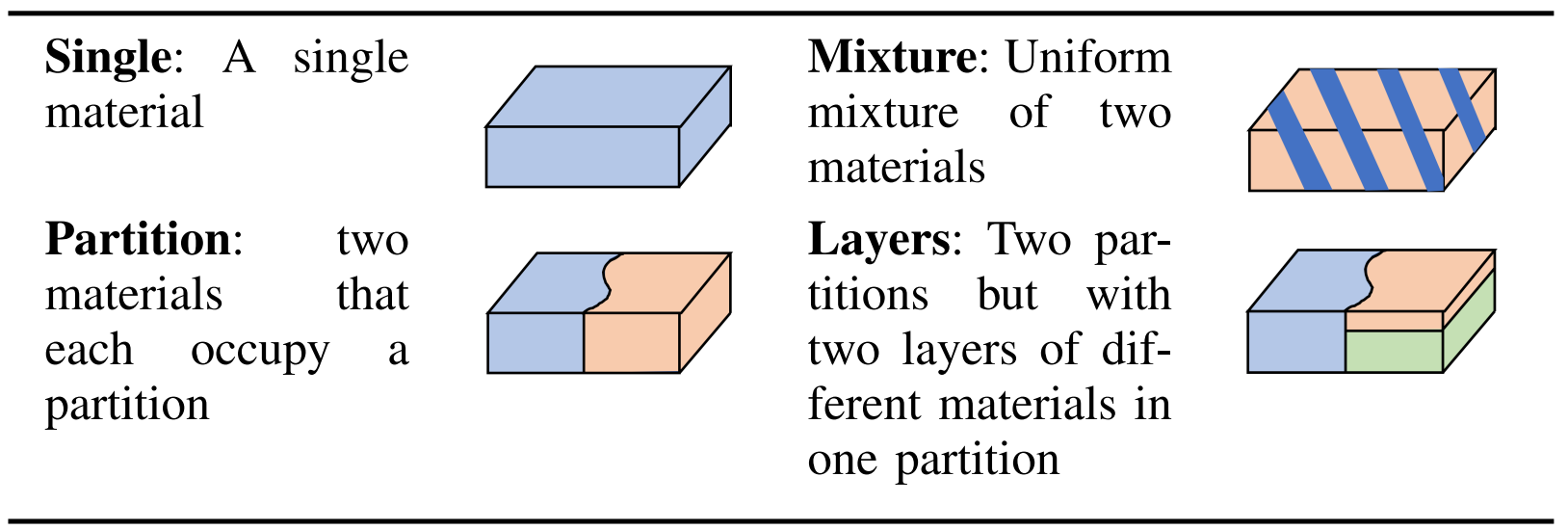
For each task (defined by materials and composition) we collect 100 samples. The dataset currently contains 6700 samples collected over 67 tasks.There are a total of 12 different materials in the dataset. The materials are composed in 4 possible ways to form terrains.

In the entire dataset, the maximum scoop volume is 260.8 cm3, while the average is 31.3 cm3.
The following videos show a step of the data collection process on some of the terrains available in the dataset.
@inproceedings{Zhu-RSS-23,
author = {Zhu, Yifan and Thangeda, Pranay and Ornik, Melkior and Hauser, Kris},
title = {Few-shot Adaptation for Manipulating Granular Materials Under Domain Shift},
booktitle = {Proceedings of Robotics: Science and Systems},
year = {2023},
month = {July},
address = {Daegu, Republic of Korea},
doi = {10.15607/RSS.2023.XIX.048}
}